- What is Python?
- Why is Python essential for Data Science?
- Versions of Python
- How to install Anaconda Distribution?
- How to use Jupyter Notebooks?
- Python Data Types
- Operators, Conditional Statements, Loops
- Lists, Tuples, Dictionaries, Sets
- Methods and Functions
- Errors and Exception Handling
- Object-Oriented Programming

About Us
The argument in favor of using filler text goes something like this: If you use real content in the Consulting Process, anytime you reach a review point you’ll end up reviewing and negotiating the content itself and not the design.
ConsultationContact Info
- Chicago 12, Melborne City, USA
- (111) 111-111-1111
- lebari@gmail.com
- Week Days: 09.00 to 18.00 Sunday: Closed
📊 Course Overview:
The Data Science Elite: Python, Power BI, SQL, and ML Mastery course is a comprehensive, instructor-led program crafted to launch your career as a high-performing data professional. Delivered through live, online classes by Microcare Academy, this course offers an immersive learning experience designed for immediate job readiness.
You'll dive deep into:
- 🐍 Python Programming for Data Analysis and Automation
- 🛢️ SQL for Database Queries and Data Management
- 📊 Power BI for Interactive Dashboards and Visual Analytics
- 🤖 Machine Learning & AI for Predictive Modeling
- 🔁 MLflow & MLOps for Model Deployment and Lifecycle Management
- 📈 Data Wrangling, Transformation, and Feature Engineering
- 🧠 Deep Learning with Neural Networks
- 🔍 Data-Driven Decision Making using Real-World Projects
Through hands-on training and real-world projects, you'll gain practical expertise in data manipulation, visualization, modeling, deployment, and performance monitoring.
💼 With dedicated placement support, this course is more than just education—it’s a career transformation platform, empowering you to thrive in today’s data-driven world.
Skills:
Tools

Course content
-
MODULE 1: FUNDAMENTALS OF PYTHON12 lectures
-
MODULE 2: DATA HANDLING WITH NUMPY AND PANDAS 22 lectures
- 2.1 Numpy
- Introduction to NumPy
- Creating arrays from Python lists and tuples
- Standard data types
- Two-dimensional arrays
- Array Attributes
- Array Indexing and Slicing
- Array Creations, Manipulations, Aggregations, and Comparisons
- Masks and Boolean Logic
- 2.2 Pandas
- Introduction to Pandas
- Pandas data types
- Data indexing and selecting
- Input and Output
- Combining and Merging
- Aggregation and Grouping
- Analyzing data with Pivot tables
- String operations
- Data transformation
- Working with date and time columns
- Conditional filtering
- Getting information about data
- Handling missing values
-
MODULE 3: DATA VISUALIZATION WITH SEABORN 13 lectures
- Overview of Seaborn
- Why visualize data?
- Plotting univariate histograms
- Kernel density estimation
- Empirical cumulative distributions
- Visualizing bivariate distributions
- Distribution visualization in other settings
- Categorical scatterplots
- Distributions of observations within categories
- Statistical estimation within categories
- Visualizing regression models
- Multi-plot grids
- Controlling figure aesthetics
- Creating interactive dashboards with Streamlit for visualization
-
MODULE 4: EXPLORATORY DATA ANALYSIS 11 lectures
-
MODULE 5: FUNDAMENTALS OF APPLIED STATISTICS 30 lectures
- 5.1 INTRODUCTION TO STATISTICS
- Definition of Statistics
- Categories of Statistics: Descriptive and Inferential
- Qualitative vs Quantitative Data
- Scales of Measurements: Nominal, Ordinal, Interval, Ratio
- Understanding data types in datasets (e.g., House sales, Churn)
- Statistical Terms and Definitions
- Population vs Sample
- 5.2 DESCRIPTIVE STATISTICS
- Measures of Central Tendency: Mean, Median, Mode, Weighted Mean, Geometric Mean, Harmonic Mean
- Pros and cons of Mean and Median
- Measures of Dispersion: Range, Interquartile Range, Mean Absolute Deviation, Variance, Standard Deviation, Z-score
- Measures of Shape: Skewness and Kurtosis
- 5.3 PROBABILITY AND PROBABILITY DISTRIBUTION
- Definition of Probability and Properties
- Counting rules
- Conditional Probability
- Bayes’ Rule
- Introduction to Probability Distribution
- Random Variables and Types
- Types of Probability Distributions
- Discrete Distributions: Binomial, Poisson, Uniform
- Continuous Distributions: Normal
- 5.4 INFERENTIAL STATISTICS
- Introduction to Inferential Statistics
- Point vs Interval Estimations
- Confidence Interval
- Sampling Distribution and Standard Error
- Central Limit Theorem
- Hypothesis Testing
- Steps for Hypothesis Testing
- Null and Alternative Hypotheses
- Type-1 and Type-2 Errors
- Level of Significance, Critical Value, P-value
- T-tests: One-sample, Two-sample, Paired
- F-test for Variance Comparison
- Chi-square Test for Goodness of Fit
-
MODULE 6: DATA PREPROCESSING 14 lectures
- Importance of Data Preprocessing in Data Science
- Data Cleaning: Identifying and Correcting Inconsistencies
- Handling Missing Values: Deletion, Imputation (Mean, Median, Mode)
- Handling Outliers: Detection and Treatment
- Data Integration: Merging and Joining Datasets
- Data Transformation: Normalization, Standardization
- Encoding Categorical Variables: One-Hot Encoding, Label Encoding
- Feature Scaling: Min-Max Scaling, Standard Scaling
- Feature Engineering: Creating New Features
- Handling Imbalanced Data: Oversampling, Undersampling, SMOTE
- Text Preprocessing for NLP: Tokenization, Stop Words Removal, Lemmatization
- Data Reduction: Sampling, Binning
- Using Pandas and Scikit-learn for Preprocessing
- Pipeline Creation with Scikit-learn for Reproducible Workflows
-
MODULE 7: INTRODUCTION TO MACHINE LEARNING 4 lectures
-
MODULE 8: REGRESSION 9 lectures
-
MODULE 9: CLASSIFICATION 10 lectures
-
MODULE 10: NATURAL LANGUAGE PROCESSING 7 lectures
-
MODULE 11: DECISION TREE 5 lectures
-
MODULE 12: ENSEMBLE LEARNING 9 lectures
-
MODULE 13: DIMENSIONALITY REDUCTION 7 lectures
-
MODULE 14: UNSUPERVISED LEARNING 8 lectures
-
MODULE 15: DEEP LEARNING 11 lectures
- Introduction to Deep Learning
- Neural Networks: Perceptrons, Multi-Layer Perceptrons (MLP)
- Activation Functions: Sigmoid, ReLU, Tanh
- Deep Learning Frameworks: TensorFlow, Keras, PyTorch
- Convolutional Neural Networks (CNNs) for Image Data
- Recurrent Neural Networks (RNNs) for Sequential Data
- Training Deep Learning Models: Backpropagation, Gradient Descent
- Regularization Techniques: Dropout, L2 Regularization
- Preprocessing Data for Deep Learning
- Tracking Deep Learning Experiments with MLFlow
- Deploying Deep Learning Models with Streamlit
-
MODULE 16: HYPERPARAMETER TUNING 10 lectures
- Introduction to Hyperparameters
- Importance of Hyperparameter Tuning
- Common Hyperparameters in Machine Learning Models
- Manual Tuning vs Automated Tuning
- Grid Search
- Random Search
- Bayesian Optimization
- Using Scikit-learn and Optuna for Hyperparameter Tuning
- Tracking Tuning Experiments with MLFlow
- Evaluating the Impact of Hyperparameter Tuning on Model Performance
-
MODULE 17: MODEL EVALUATION AND VALIDATION 10 lectures
- Importance of Model Evaluation
- Train-Test Split
- K-Fold Cross-Validation
- Stratified K-Fold for Imbalanced Data
- Performance Metrics for Regression: MSE, RMSE, MAE, R²
- Performance Metrics for Classification: Accuracy, Precision, Recall, F1 Score, ROC-AUC
- Overfitting and Underfitting
- Learning Curves and Validation Curves
- Using Scikit-learn for Model Validation
- Logging Evaluation Metrics with MLFlow
-
MODULE 18: MLOPS AND MODEL DEPLOYMENT 9 lectures
- Introduction to MLOps
- MLOps Lifecycle: Data, Model, Deployment, Monitoring
- Using MLFlow for Model Management and Deployment
- Model Versioning and Registry
- Continuous Integration and Deployment for ML
- Monitoring Model Performance
- Building and Deploying Data Apps with Streamlit
- Containerization with Docker for ML Models
- Scalable Model Deployment with Cloud Platforms
-
MODULE 19: POWER BI 10 Topics + Projects
-
MODULE 20: PROJECTS 6 lectures
- End-to-End Data Science Projects
- Incorporating Data Preprocessing Pipelines
- Using MLFlow for Experiment Tracking and Model Management
- Hyperparameter Tuning for Optimized Models
- Deploying Project Dashboards with Streamlit
- Example Projects: Predictive Modeling, NLP Applications, Clustering Analysis, Deep Learning Applications
Career Progression and Salary Trends
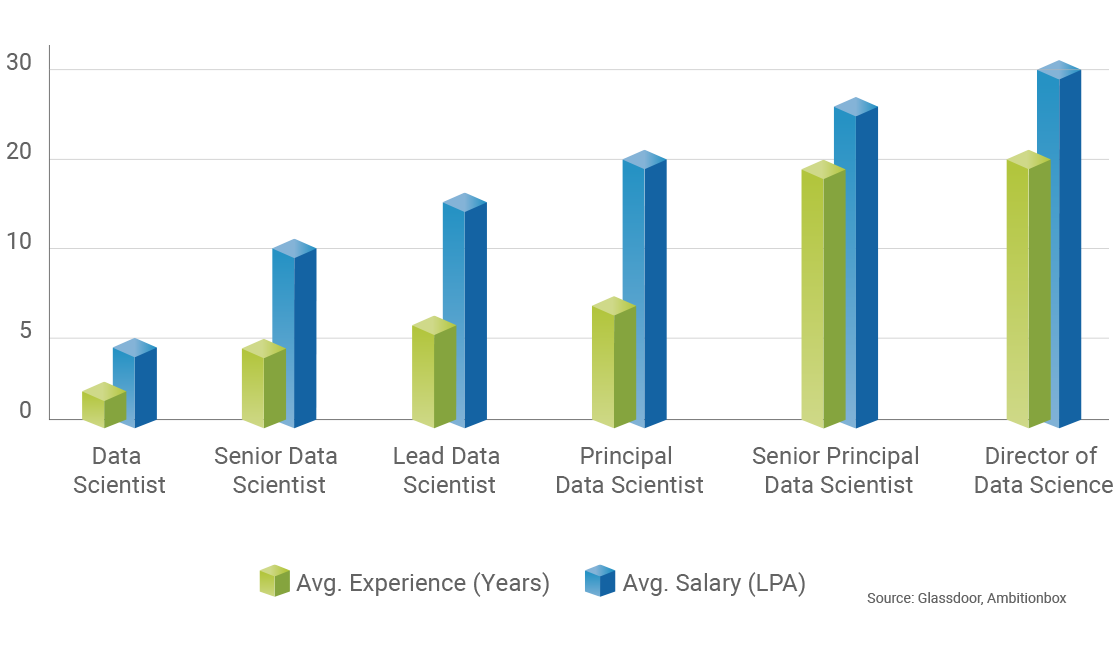
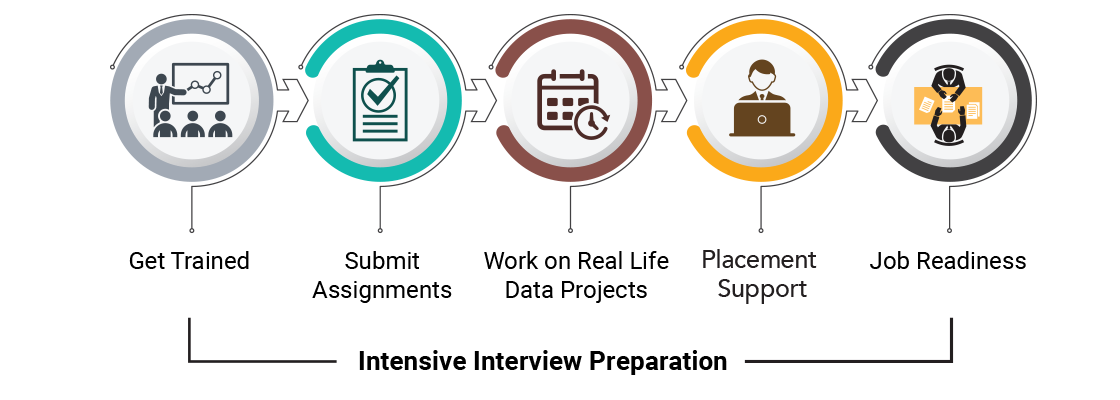
Learning Path
RS. 30,000RS. 40,000
Why Microcare Academy:
- Comprehensive Curriculum
- Expert-Led Live Classes
- Real-Time Industry Projects
- Certificate of Completion